本記事はblog.juniper.netに掲載されている"AI/ML Data Center Networking on Ethernet"の抄訳と、補足を追加したものです。
-----
これは、AI基盤のオンプレミス環境のデータセンターにおけるネットワーキングが果たす重要な役割を説明する一連の技術ブログの初回の記事です。
このブログでは、AI/MLのワークロードのデータ転送プロトコルと輻輳に関する考慮事項について説明します。
このシリーズでは、ファブリックにおける輻輳制御や負荷分散、エンドポイント (またはエンドポイント支援) によるアプローチなど、さまざまな技術を取り上げます。
イーサネット上の AI/ML データセンター ネットワーキングの現状と進化
AI/ML ワークロードにおいて、大規模なデータセットをどのように処理するかは重要な課題です。
計算を GPU で行うことで、このタスクが大幅に高速化することができます。例えば、CPUでは1日以上かかる処理がGPUでは10分程度で終わることもあります。
ただし、この処理を行うには、多くの場合、単一 GPU のメモリ容量を超えており、妥当なジョブ完了時間を達成するには複数の GPU を利用するのが一般的です。
AIを利用する過程として、”学習/トレーニング”と”推論/インファレンス”という大きく2つのプロセスがあります。”学習/トレーニング”とは、大量のデータから特徴のパターンを作り出すプロセスです。このトレーニングには多くの時間と計算資源が必要になり、多くの複数のGPUで並列処理をすることになります。
このようなワークロードを処理する基盤を用意するには、 AI/ML フレームワークとユースケースに基づいてさまざまな考慮が必要になり、どのようにGPU ノードのクラスター全体にデータと計算を分散するかを検討する必要があります。即ち、複数の各ノードのGPUをネットワークでどのように接続させる考慮が必要です。
皆様はすでにご存じもしれないですが、AI データセンターのコストは主に使用される GPU の数によって決まります。GPUの性能は非常に高いですが、一般的に非常に高額となり、1台でも数百万から数千万以上の費用が必要になります。また、クラウド上でGPUを利用する場合でも数億規模のコストが必要になる場合があり、使いたい時に使うことができない、パフォーマンスが充分でないという理由などからも、ある程度の規模になる場合は、オンプレで基盤環境を準備することが推奨されることがあります。
高価なGPUを使わずにアイドル状態にしておくのは、投資対効果が低くなってしまいます。アイドル状態の GPU リソースを無駄にしないために、GPU ノードを相互接続する高性能ネットワークが必要です。ネットワークで速度が低下すると、高価な GPU の使用率が低下し、ジョブの完了時間にも悪影響を及ぼす可能性があるためです。例えば、昨年、MetaはAI/MLトレーニングの経過時間の33%がネットワークの待機に費やされていることを発表しています。
ハイ パフォーマンス コンピューティング (HPC) に由来するリモート ダイレクト メモリ アクセス (RDMA) を利用したアプローチは、現在 AI/ML クラスター通信で広く使用されています。 RDMA は、ネットワーク上の GPU (GPU ノード) を搭載した複数のコンピューティング リソース上のリモート メモリ間のゼロコピー転送を可能にすることで、効率的なデータ転送を可能にします。これは、ネットワーク インターフェイス カード (NIC) に実装されたReliable Connection (RC) トランスポート プロトコルを使用して行われ、CPU または GPU にほとんど、またはまったく負荷をかけません。但し、もともと InfiniBand ネットワーク用に設計された RC には、ロスレス ネットワークとしてパケットドロップがない環境や、順序どおりのパケット配信などの厳しい要件があります。
RDMA + イーサネット = ROCEv2
AI/ML トレーニング クラスター ネットワーキングの状況では、InfiniBand の代替としてイーサネット ベースのネットワークを検討することの関心が高まっています。イーサネット ネットワークで RDMA を有効にするために、RDMA over Converged Ethernet バージョン 2 (ROCEv2) が開発されました。これは、イーサネット ネットワーク上での転送用に RDMA/RC プロトコル パケットを UDP パケット内にカプセル化するプロトコルです。
AI/MLネットワークのイーサネット 利用については、よりオープンでロックインの無い環境となり、柔軟にさまざまなエコシステムが活用されることが期待されています。The Linux Foundationが2023年7月19日に設立を発表したネットワーク規格策定団体「Ultra Ethernet Consortium(UEC)」が推進している団体の一つとなり、Juniper Networksも加入しています。
IPベースのイーサネット ファブリック
データセンタの一般的なアーキテクチャでは、リーフ層とスパイン層を特徴とする Clos トポロジを利用するのが一般的です。
学習/トレーニングを行うGPU間のネットワークは、推論/インファレンスとは別のネットワークを作ることが推奨されます。推論/インファレンスを利用するネットワークは、フロントエンドネットワークとも言われ、ある程度はロスが許容できるネットワークになり、従来のデータセンターと大きく要件は変わりません。学習/トレーニングを行うGPU間のネットワークは、バックエンドネットワークとも呼ばれ、高額で高パフォーマンスのGPUを有効活用するには、高帯域のノンブロッキング ネットワークを提供することが推奨されます。
ノンブロッキングを実現するには、すべてのリーフからノードへのポートの累積帯域幅が、すべてのリーフからスパインへのアップリンク ポートの合計帯域幅と一致するか、それ未満である必要があります。つまり、オーバーサブスクリプションではない帯域設計を行う必要があります。
この設計により、リーフ スイッチとスパイン スイッチ間のネットワークで、速度が低下することなく、各ノードが全帯域幅を使用できるようになります。
帯域の有効活用にはトラフィックの輻輳制御も重要です。
リーフスパイン アーキテクチャ内では、主に次の 3 つの主要な領域で輻輳が発生する可能性があります。
-
リーフとスパインの間 (スパイン方向のリーフ ポートの TX送信 キュー):
リーフ スイッチからスパイン スイッチへのデータ送信中に輻輳が発生することがあります。リーフ ポートの TX 送信キューで輻輳が発生し、これらのスイッチ間の通信に影響を与える可能性があります。
-
スパインとリーフの間 (リーフ方向のスパイン ポートの TX 送信キュー):
スパイン スイッチからリーフ スイッチへのデータの送信中に輻輳が発生することがあります。スパイン ポートの TX 送信キューで輻輳が発生し、これらのスイッチ間の相互通信に影響を与える可能性があります。
-
リーフとノード間(ノード方向のリーフ ポートの 送信TX キュー):
リーフ スイッチから各ノードへのデータ フローで輻輳が発生することがあります。リーフ ポートの送信 TX キューで輻輳が発生し、リーフ スイッチと接続されたノード間の通信に影響を与える可能性があります。
それぞれ、どのような状況で輻輳が発生するかを示します。
リーフからスパインの輻輳
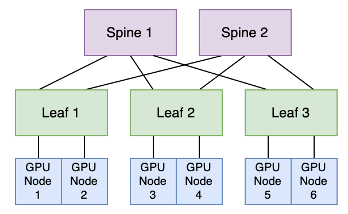
この例では、1 つのリーフ スイッチに接続された GPU ノードは、別のリーフ スイッチに接続された GPU ノードと通信するためには、 2 つの潜在的なルートがあります。
GPU ノード 1 および 2 は、「リーフ 1、スパイン 1 およびリーフ 2」または「リーフ 1、スパイン 2 およびリーフ 2」のいずれかを介して GPU ノード 3 および 4 との接続するいことができます。
選択するパスの決定は、等コスト マルチパス (ECMP) ロード バランシング アルゴリズムを使用して、リーフ スイッチによって行われます。
ECMP は、受信パケットの特定の属性 (送信元/宛先 IP アドレス、送信元/宛先ポート、プロトコルなど) に基づいてハッシュを生成することによって動作します。同一のハッシュを持つ後続のパケットは、スパインに向かう同じアップリンクに送信され、ECMP で同一の「フロー」として認識されます。それぞれのフローがどのアップリンクを利用するかは、ハッシュ値マッピングやモジュロ N マッピングなどのさまざまな方法を使用して決定されます。
ECMP は、各フロー内のパケット順序を維持しながら、利用可能なアップリンク全体にパケットを均等に分散することを目的としています。この方法は、複数のノードにまたがる多数の短期間のセッションがセッションごとに異なるハッシュを作成する一般的な TCP ベースのアプリケーションで効率的に機能し、多様なアップリンク間での分散を確保します。
ただし、存続期間の長いフローでは課題が発生します。複数の高帯域幅フローが同じアップリンクを共有するためにハッシュされるシナリオの場合、その特定のリンクで利用可能な帯域幅を超える可能性があり、輻輳の問題が発生します。
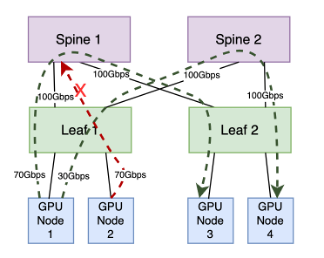
上の図では、特定のリーフとスパインの間で は、2 つのパスがあり、合計 200 Gbps の帯域幅を利用できます。 GPU ノード 1 は 2 つの長期フローを生成します。1 つは最初のパス経由で 70 Gbps を消費し、もう 1 つは 2 番目のパス経由で 30 Gbps を消費します。 GPU ノード 2 は、70 Gbps を利用する存続期間の長いフローを生成します。 2 番目のパスにはこのフローに対して十分な容量がありますが、ECMP アルゴリズムにより、このフローが 30 Gbps の容量しか残っていない最初のパスに配置される可能性があります。この不一致により、最初のパスが過負荷がになり、リーフ ポートの TX キューに輻輳が発生し、最終的にはパケットのドロップにつながる可能性があります。この分散の根本原因は、ECMP の単純さにあります。パス選択におけるリンクの使用率と品質についての考慮が欠如しており、代わりにフロー数に基づく基本メカニズムに依存しているためです。
スパインからリーフの輻輳
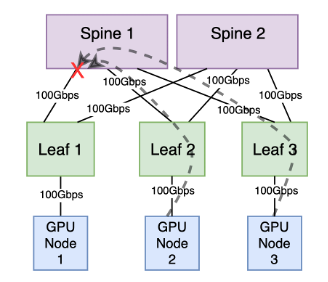
この構成では、リーフ 2 にリンクされた GPU ノード 2 と、リーフ 3 に接続された GPU ノード 3 が全帯域幅でデータを同時に送信し、それぞれがリーフ 1 に接続された GPU ノード 1 に 100Gbps トラフィックを提供します。 リーフ 1、2、および 3それぞれ 100Gbps 接続を備えた 2 つのスパインに冗長接続します。各リーフとスパイン層の間で利用可能な合計帯域幅は 200Gpbs です。
ただし、リーフ 2 とリーフ 3 の両方が同じスパインへのアップリンクを利用する場合、受信側 GPU ノードに接続されているリーフ スイッチへのスパイン ポートの 送信TX キューで輻輳が発生します。
リーフからノードの輻輳
次の潜在的な輻輳ポイントは、リーフ スイッチとノード間の通信で発生します。特に、複数の送信者が 1 つの受信者にデータを送信し、受信者の帯域幅容量を超える場合に発生します。これは「インキャスト」輻輳として知られています。
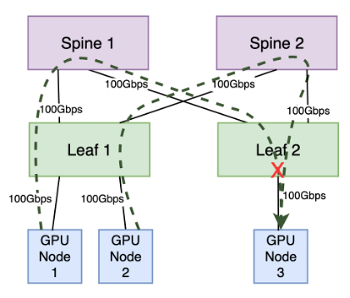
すべてのノード ポートが 100 Gbps の帯域幅容量を備えていると仮定すると、GPU ノード 1 と 2 は合計で最大容量で送信し、合計 200 Gbps になります。この例では、リーフとスパイン間は、受信ノードが接続されているリーフ スイッチ宛てのトラフィックを適切に処理できます。ただし、GPU ノード 3 が接続されているリーフ ポートの帯域幅容量は 100 Gbps のみです。その結果、このポート宛てのトラフィックの半分は、ポートの容量が限られているためにドロップされます (フロー制御や輻輳管理がない場合)。
AI/MLワークロードのネットワークの影響
- 従来の ECMP では、特に AI/ML ワークロードで利用される長時間にわたる高帯域幅 (「エレファント」) フローの場合、リーフ スイッチとスパイン スイッチの間で最適とは言えないネットワーク利用、輻輳、パケット ドロップが発生する可能性があります。AI /ML環境では一般的なワークロードよりフロー数は少なく、帯域は多く消費する傾向があるため、どのようにこれらを最適にバランスさせるかという施策が必要です。
- 送信側の帯域幅の合計が受信側の容量を超えると、リーフからノードのポートで輻輳が発生し、パケット ドロップが発生する可能性があります。
ネットワーク利用率を向上させるために、「フローレット」と呼ばれる、転送期間が分かれたフローを別のフローとするFlowletベースのバランシングや、パケットごとにトラフィックを分散するパケット スプレーを利用したり、利用帯域状況を考慮する、動的ロード バランシング (DLB, Dynamic Load Balancing)など、いくつかの強化された負荷分散技術が登場しました。ただし、DLB だけでは RDMA トラフィックには最適化できない場合があり、パケットごとにトラフィックを分散するパケットスプレイにより順序が狂ったパケット転送が発生する可能性があります。このような技術とその影響については、このシリーズの後続のブログで説明します。
イーサネット ファブリックでは、損失の多いネットワークの課題は通常、プロトコル レベル (TCP など) またはアプリケーション レベル (UDP を使用した VoIP など) で管理されます。これらのプロトコルとアプリケーションは、イーサネット環境で効率的に機能するように特別に設計されています。
ただし、RC プロトコルを使用する RDMA は、もともと、ロスレスで順序どおりのパケット配信を行う InfiniBand ファブリック用に設計されたものであるため、課題が生じます。 RC プロトコルは、パケット損失や順序どおりでないパケット配信に対して非常に敏感です。 RC では、パケットは順序付けされており、パケットがドロップされたり順序が狂って到着した場合、NIC は、最後に確認応答されたパケットからすべてのパケットを再送信する「go-back-N」メカニズムに基づいて再送信を要求する場合があります。パケットのドロップによるタイムアウトの結果として、接続を切断して再確立する必要がある場合もあります。これにより通信パフォーマンスが大幅に低下し、その結果、GPU 使用率が低下し、AI/ML クラスターでのジョブの完了時間が長くなります。
よって、ROCEv2 のイーサネットでのパケット損失、配信順序の乱れ、輻輳の問題に対処するには、代替メカニズムを採用する必要があります。
AI/MLのネットワークファブリック要件をどのよう実現するか
AI/MLのファブリックの主な要件は、ロスレス パケット転送です。これは、優先順位ベースのフロー制御 (PFC, Priority-based Flow Control:802.1Qbb) と呼ばれるフロー制御技術によって実現されます。この手法は優先度ごとに独立して動作します 。これにより、受信者は、直接接続されている送信者を一時停止できます。受信側の受信バッファが敷値レベルに達すると、受信側は送信側にポーズ フレームを送信して、送信側がそれ以上フレームを送信するのを一時的に停止します。バッファ敷値は、送信者がフレームの送信を停止する時間を確保し、受信者がバッファがオーバーフローする前にすでに回線上にあるフレームを受け入れることができるように、充分に低くする必要があります。受信バッファが別の敷値を下回るレベルまで空になると、受信側は一時停止フレームのタイムアウトを0 に設定するメッセージを送信し、送信を再開します。
PFC は、ヘッドオブラインブロッキング、輻輳の拡散、さらにはデッドロックなどの望ましくないネットワーク動作を引き起こす可能性があります。これにより、明示的輻輳通知 (ECN, Explicit Congestion Notification:RFC3168) を PFC と組み合わせて使用することが推奨されます。この技術を使用すると、ネットワーク内の差し迫った輻輳がトラフィック ソースに報告され、トラフィック ソースの送信レートを低下させることができます。送信レートは、アプリケーションが使用する通信送信キューと受信キューに対応する NIC ハードウェア リソースである RoCE キュー ペア (QP, Queue Pair) ごとに制御されます。
ECN は、両方のエンドポイント (NIC) とエンドポイント間のすべての中間スイッチで有効にします。ネットワーク デバイスは、IP ヘッダーの TOS フィールドの ECN フィールドを使用してパケットをマークします。 ECN マークの付いたパケットが宛先 NIC に到着すると、輻輳通知パケット (CNP, Congestion Notification Packet) が送信元 NIC に送信され、送信元 NIC は CNP で指定された QP の送信レートを下げることでできます。 ECN の敷値はスイッチに設定されます。これは出力敷値です。出力キューがこの敷値を超えると、スイッチはそのキュー上のパケットに ECN マーキングを開始します。
RoCEv2 の PFC と ECN の組み合わせは、データセンター量子化輻輳通知 (DCQCN, Data Center Quantized Congestion Notification) 、または、RoCEv2 輻輳管理 (RCM, RoCEv2 Congestion Management)と呼ばれます。
この手法を正しく動作させるには、PFC と ECN の敷値を最適な値に設定し、次の要件のバランスを取る必要があります。
- PFC が早すぎないように、つまりフローを遅くするために ECN に輻輳フィードバックを送信する機会を与える前にトリガーされるようにします。
- PFC のトリガーが遅すぎて、バッファ オーバーフローによるパケット損失が発生しないようにします。
このアプローチの詳細な説明と研究については、
Congestion Control for Large-Scale RDMA Deploymentsの文書を参照してください。
DCQCN 手法は最も普及しているアプローチであり、実際RoCEv2 は多くの環境で利用されています。ただし、PFC および ECN の敷値を何の情報も無く正しく設定するのは困難な場合があります。また、最適なネットワークを実現するには、ネットワーク上の負荷を把握し、適切に分散ができているか確認することも重要です。エンドツーエンドでネットワークを最適化する必要がありますが、これらについては、このシリーズの今後のブログの主なトピックになります。
エンドツーエンドのアプローチでネットワーキングを最適化することは、新しい概念ではありません。システム設計におけるエンドツーエンドの議論は、研究分野でも多くの有用な情報を提供しており、以下に引用します。
- https://web.mit.edu/Saltzer/www/publications/endtoend/endtoen d.pdf – システム設計におけるエンドツーエンドの議論 /End to End Arguments in System Design – Salzer、Reed & Clark
- http://nms.lcs.mit.edu/6829-papers/bravenewworld.pdf – インターネットの設計を再考する: エンドツーエンドの議論と勇敢な新しいものワールド/ Rethinking the Design of the Internet: The end to end arguments vs the brave new world,、Clark & Blumenthal
JuniperのAI/ML向けのデータセンターソリューションとしては、QFX, PTXのハードウェアスイッチや必要とされるソフトウェア機能に加えて、Apstraによる即時展開・自動化・可視化の利用が可能です。また、事前に充分評価されたデザインであるJVD(Juniper Validated Design)も有り、さまざまなケースのベストプラクティスがご利用できます。DCQCNのファインチューニングについても実施方法やプロフェッショナルサービスの提供も可能です。
今後、これらの情報も公開させていただく予定です。
AI/ML向けのデータセンターソリューションの情報については、これらもご参照ください。
- Juniper AI Data Center Networking
- Designing Data Centers for AI Clusters
- Youtube:RDMA Over Converged Ethernet Version 2 for AI Data Centers
- Cloud Field Day 18-Automating AI Cluster Design with Juniper Apstra