本記事は、blog.juniper.netに掲載されている"Automating AI Training Clusters with Juniper Apstra"と、"Don’t Let Your AI Get Caught in Traffic"を抜粋後に抄訳し、補足を追加したものです。
以前の記事では、イーサネットによる AI/ML データセンター ネットワーキング概説を記載しました。
今回は、Juniper Apstraを使ってどのようにAI/ML データセンター ネットワーキングを自動するのかご説明します。
AI クラスターで高い性能を実現するためには、ネットワークが重要です。ネットワーク ベンダーが言うのは簡単ですが、さまざまな調査結果から、それは真実だということがわかります。
Juniper Networksでは、AI の力を最大限利用するということは、AI モデルにおけるトレーニング のパフォーマンスと GPU ジョブの完了時間(JCT:Job Completion Time)に対して、ネットワークが ボトルネックにならないようにすることが重要だと考えています。
Juniper CEO の Rami Rahim は、AI データ センターのネットワーキングに対するジュニパーのアプローチ、として、"1.高パフォーマンス ハードウェアポートフォリオ"、"2.イーサネットに代表されるオープンスタンダード技術"、"3.エクスペリエンス重視"、により、AIのデータセンターにどのような変化をもたらすことができるかについて説明しました。
"エクスペリエンス重視"のひとつとして、JuniperのApstra を利用するした構築運用負荷の軽減があります。AI ネットワークの作成をどのように容易にすることができるのかについて解説します。
Rails of the Road/レール最適化
Juniperは、NVIDIA 、Intel、AMD、など様々なGPUベンダーと共同して、推論やトレーニング用のAIクラスターソリューションに取り組んでいます。
当社のお客様から、NVIDIA に関連した質問をもらうのは、NVIDIAのGPUの卓越した需要のためだけでなく、NVIDIA社のDGX サーバーや、HGXと呼ばれるGPUボードを搭載した他のベンダーのサーバーを導入する際に、NVIDIA が従来のネットワークとは異なる、データセンター ネットワーク アーキテクトを驚かせるようなネットワークのデザインを規定しているためでもあります。これは、「rail optimization/レール最適化」と呼ばれるデザインです。
rail optimizedされた設計は、NVIDIA Collective Communications Library (NCCL) と呼ばれる複数GPU のための集合的な標準コミュニケーションルーチンのライブラリ、および、 PXN 機能 と呼ばれる内部リンクやPCI通信の技術により、ネットワーク トポロジを検出し、通信遅延を最適化することからデザインされています。つまり、GPU間の通信を最適化するデザインと機能を提供しています。
レール最適化設計の詳細については、NVIDIA のブログをご覧ください。
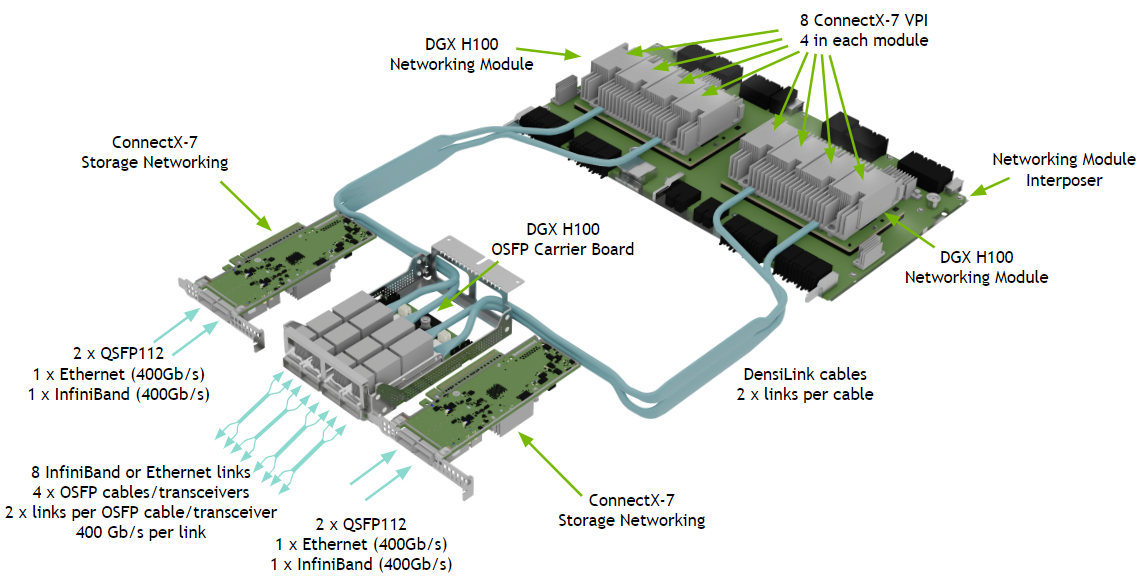
各GPUサーバーには、通常、8 つの A100 または H100 GPU を接続する NVIDIA NVLink スイッチが含まれていることも知っておく必要があります。
各サーバーには、複数のNICを搭載しており、アウトオブバンド管理インターフェイス、フロントエンド管理インターフェイス、およびストレージ インターフェイスとは別に、 バックエンドネットワークと呼ばれるGPU間通信のために、GPUごとに1つの、8 つのネットワーク インターフェイスがあります。
これらは、各A100 および H100 の 200GE または 400GE インターフェイスです。各 GPU のインターフェイスが個別のリーフ スイッチにケーブル接続される構成となります。
各サーバーは 8 つのリーフ スイッチに接続され、GPU コンピューティング ファブリックのリファレンストポロジーが作られます。
例えば、以下のDGX H100サーバーでは、4つのOSFPのそれぞれが、OSPF毎に2リンクの400 Gppsのcable/tranceiverを利用し、各GPU毎にネットワークアクセスを提供します。
これらのサーバーを備えた AI クラスターでは、フロントエンド、ストレージ、バックエンドの GPU 向けのネットワークは、通常、それぞれ、別の専用ネットワークとして構成することが推奨されます。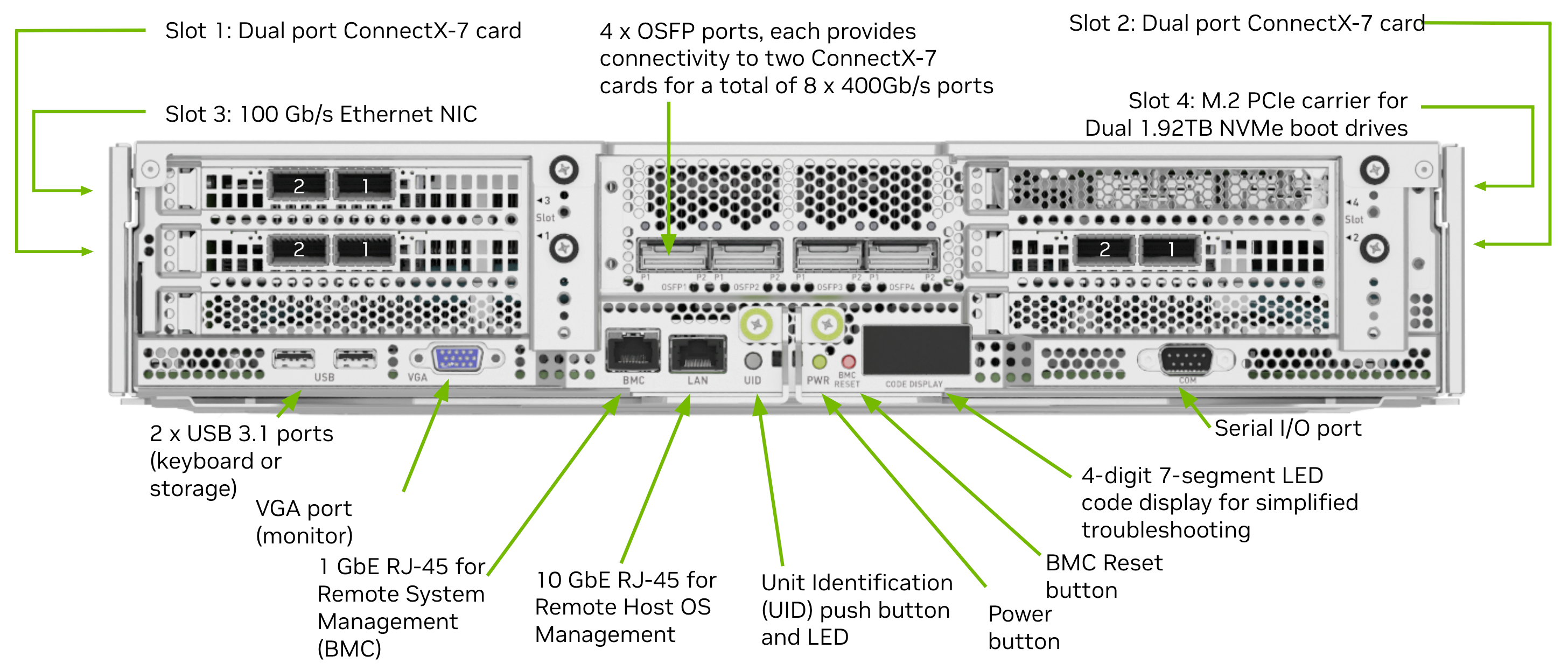
Apstra により Rails 構成を標準化する Juniper Apstra をご存じの方は、 複数のファブリックを同じ Apstra インスタンス内のブループリントとして管理できることを知っていると思います。すなわち、AI clusterで利用する各専用ネットワークをひとつのコントローラーで管理するということができます。もしApstraをご存知ない方は、こちらの記事も参考にしてください。
Apstraは、IBN(Intent Based-Networking) というアーキテクチャを採用しており、作りたい構成(Intent、意図する構成)を先に定義することによって、その構成を自動的に作成するということができます。
Apstraのインテントベースの設計コンポーネントの構築や設定をより容易にするために、サーバー用の論理デバイスや、AIクラスタのGPUファブリックで一般的なスイッチング・ポートプロファイルなど必要な構成設定をすぐに利用することできるようにする、Apstra 用 Terraform プロバイダーを利用するための構成ファイルをGithub上に公開しました。Apstra でTerraformを利用することで、Apstraで必要な設定を宣言的に設定することができます。また、それらの構成ファイルをGit上で管理することで、Gitによる設定管理や承認管理も利用した設定管理を利用することもできます。
GPU ファブリックは、多くのネットワークエンジニアにとって少し独特でもあるため、ここでは GPU ファブリックに焦点を当てます。
公開しているTerraformファイルを利用することで、GPUネットワークの各スイッチをどのように設定するかのサンプルを確認することもできます。現在、Githubに公開しているai cluster用のTerraformサンプルについては、以下2つがあります。
ai-cluster-designs
Apstraの論理デバイス、ラック、テンプレートを展開し、AI GPUトレーニング、ストレージ、フロントエンド管理のためのネットワークファブリックを設計するterraformコンフィグ一式。設計例として、64サーバ(512 GPU)、128サーバ、256サーバ、およびそれ以降のNVIDIA規定のレールに最適化されたトポロジが含まれます。
ai-cluster-jvd
AIクラスタの3つのファブリックのTerraform 構成: GPUバックエンド、ストレージ、フロントエンド管理のネットワークを構成するサンプル。この例では、2つのNVIDIAレール最適化グループにQFXのLeafスイッチとPTXのSpineスイッチを利用し、オプションでA100とH100ベースのサーバーを組み合わせた小規模クラスタ設計を利用することができます。
これらのTerraformの利用方法は、大きくは以下のステップを行うだけです。
詳しくは、GithubのReadmeを参照してください。
- Terraformのインストール link
- Githubから該当のディレクトリをダウンロード
- provider.tfのURL(apstra_user, apstra_pass含む)を利用する環境に変更
*ai-cluster-jvdをApstrsa 4.2.0で利用する場合、アップロードされているQFX5230用のDevice ProfileをImportする必要あり - %terraform initにより作業ディレクトリの初期化
- %terraform planにより実行計画の確認
- %terraform applyによる実行 (yesで実行)
また、ApstraのTerraformオペレーションステップはこちらのLab Documentサイトも参考にできます。
Apstraでは、作りたいネットワーク構成を定義するために、事前に定義設定が必要ですが、Terraformを使うことで、以下の図に示すような、A100 ベースのサーバーと H100 ベースのサーバーの 8 つの 200GE または 400GE インターフェイス用の構成を容易に生成することができます。
他にも、AI クラスターに必要な論理デバイス プロファイル含めて必要な定義ファイルを自動的に生成することになります。
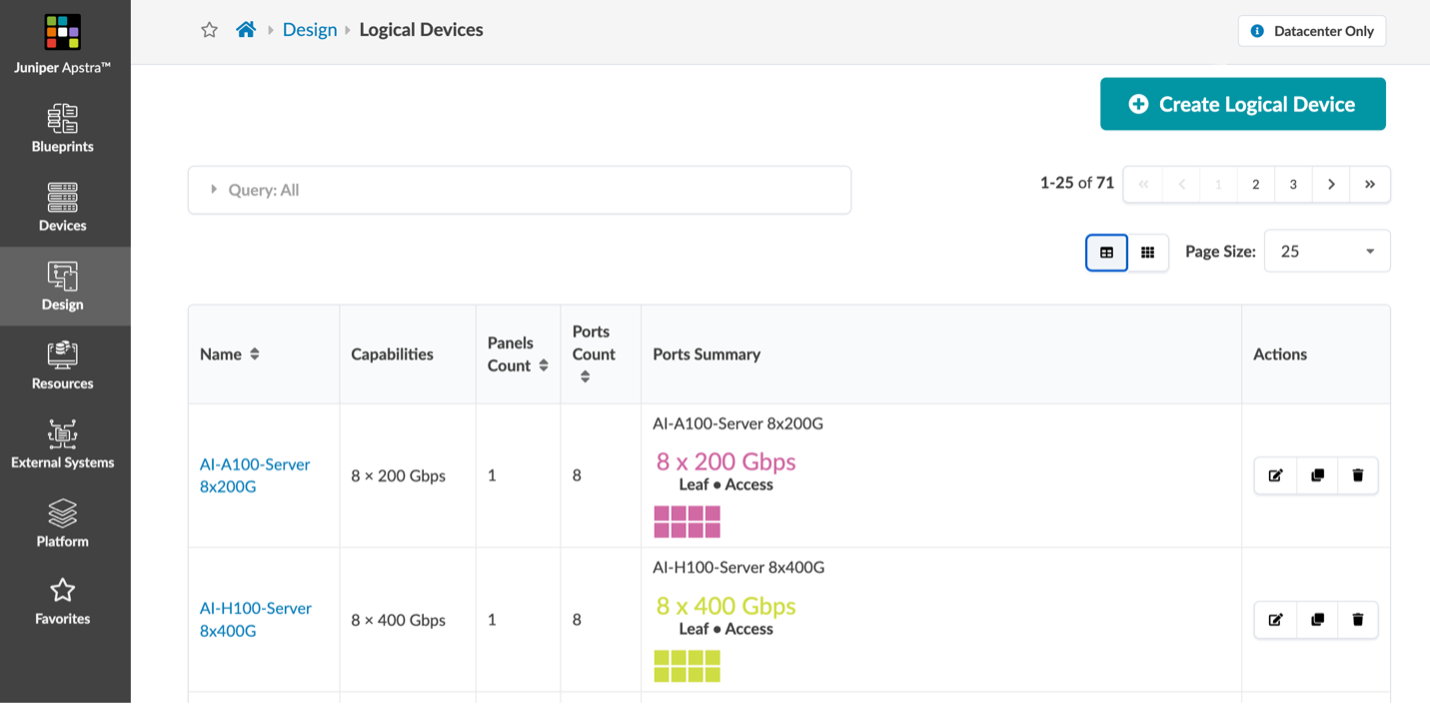
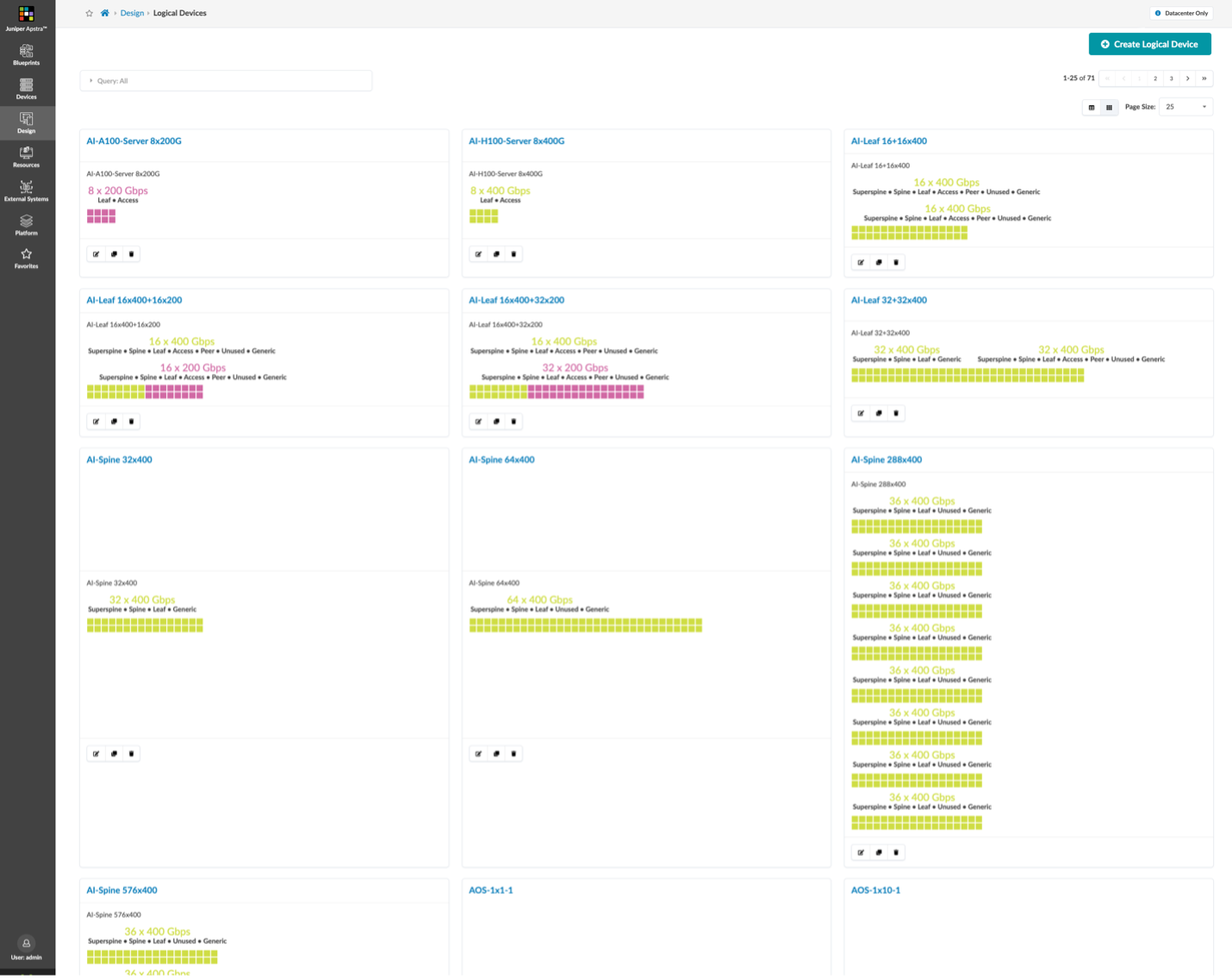
この例では、Apstraの「ラック」として 各GPUサーバーから8 つのLeafに接続するRail Optimizationの構成をモデル化しています。
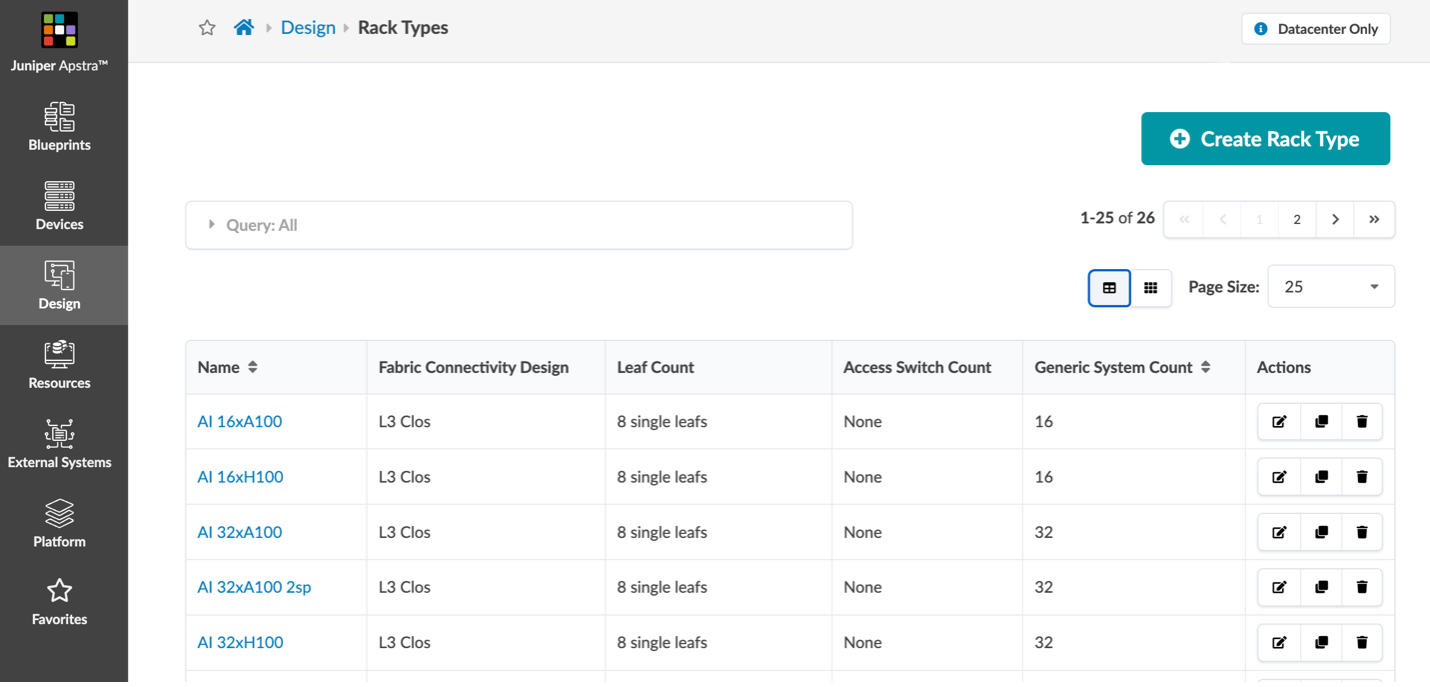
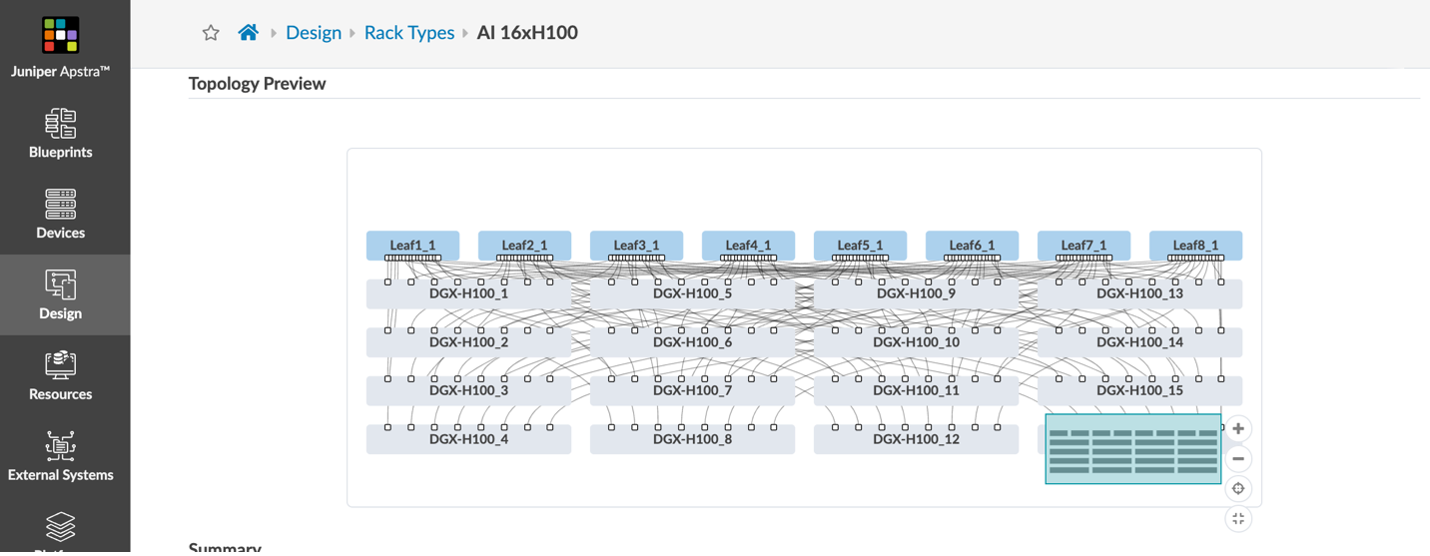
図 3 と図 4 では、QFX5220 リーフ スイッチ と、PTX10000 シャーシベースのスパイン スイッチ
を利用し、400GEを利用したベストプラクティスに基づいた構成をモデル化しています。
Super Spineを利用する5 ステージの Clos トポロジを構成するのではなく、Leaf Spineの2層 の大きなファブリックを利用する構成となっています。このテンプレートの例では、9,000 個を超える GPU を接続することができます。
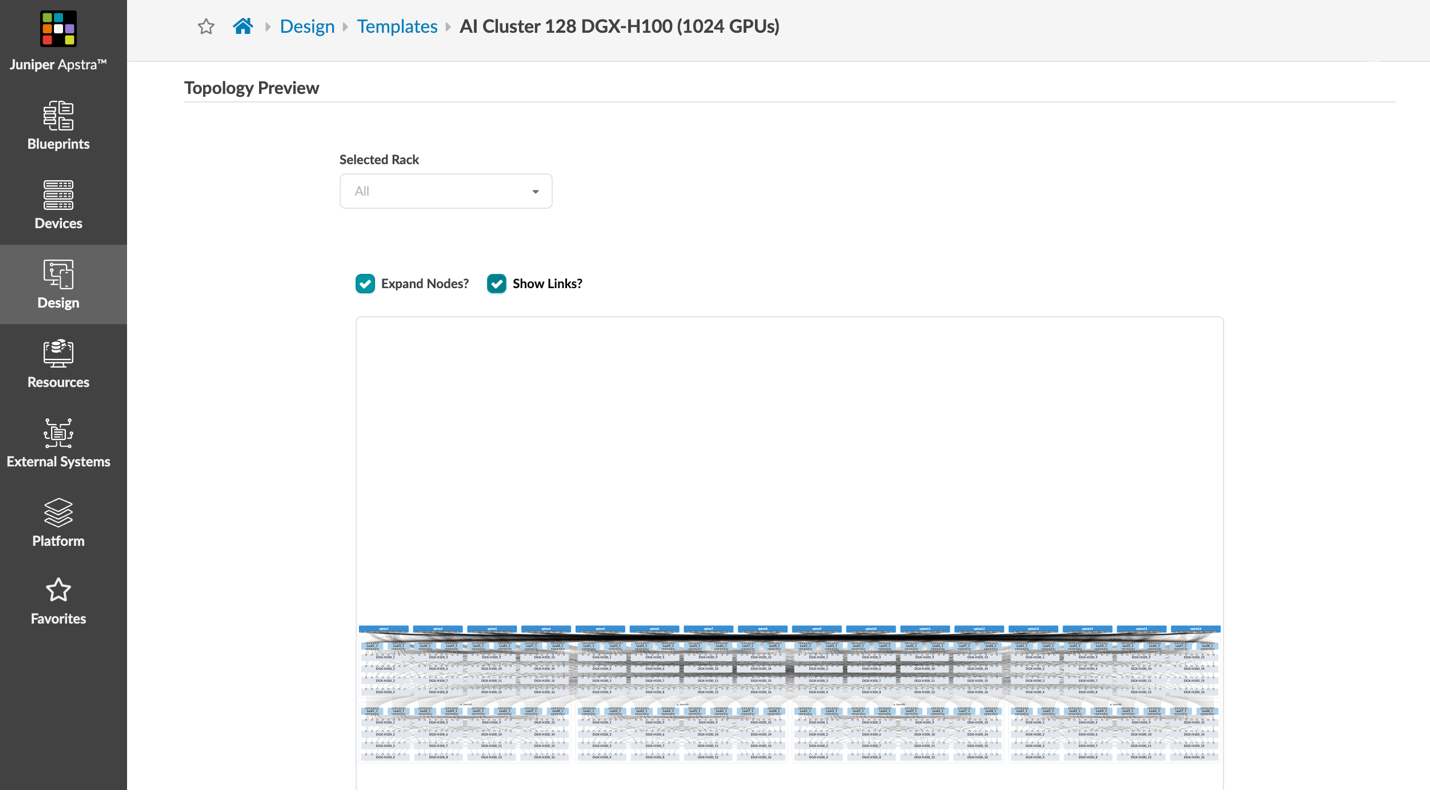
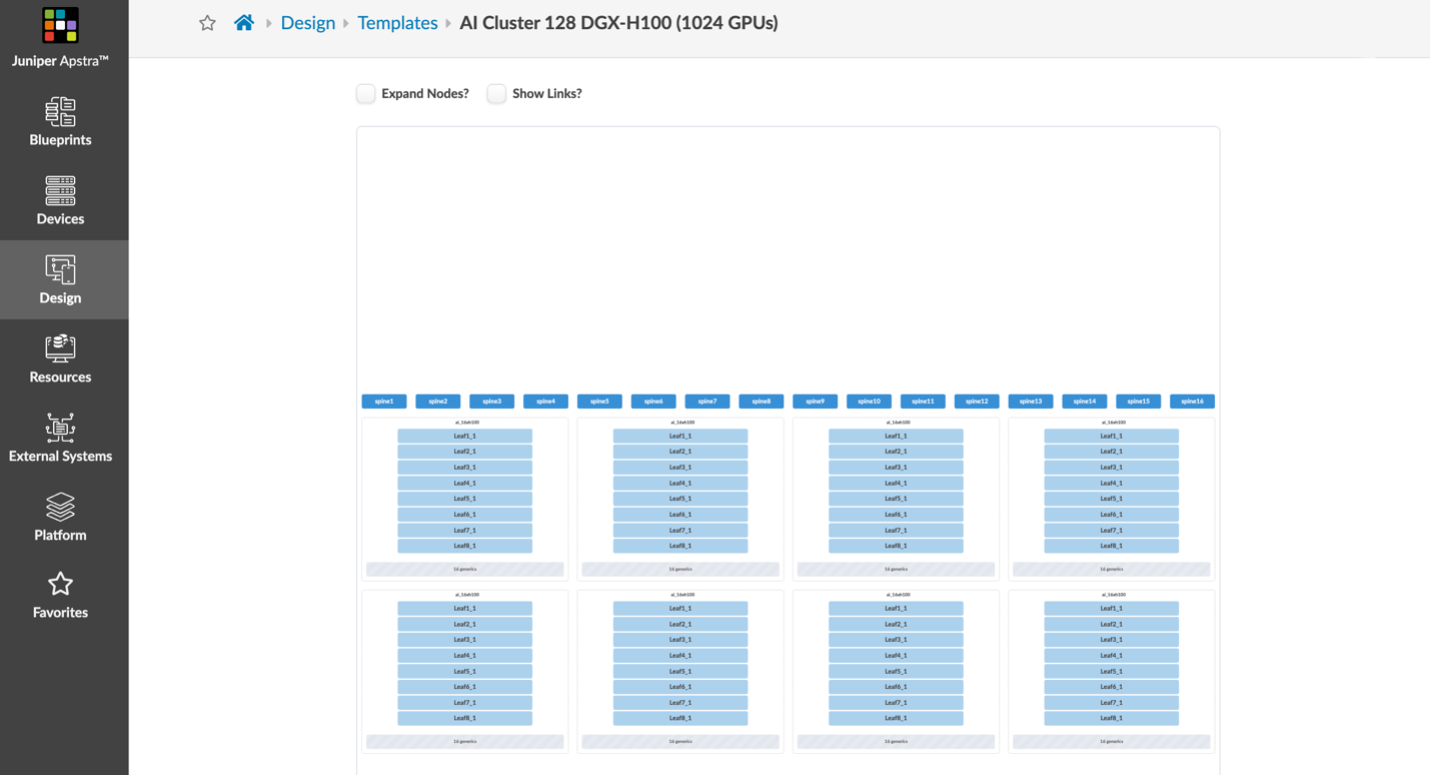
Githubのai-cluster-jvdではテンプレートだけでなく、Blueprint設定の展開も行います。
図 7: 3つのブループリント・ファブリックの展開
図 8: GPU Fabricで展開されるファブリックのサンプル
図 9: 各デバイスの接続状況は設定されるコンフィグの確認
Apstraでは、実デバイスが無くても、Apstraで自動生成されるコンフィグの確認ができ、AI Clusterに必要なDCQCNやCoS設定等も含めたサンプル設定の確認ができます。
Juniper Apstra と Terraform を使用した AI クラスター ネットワーク設計の自動化の詳細については、以下のデモをご覧ください。
AI データセンター ファブリックのさらなる追加予定
ネットワークが AI クラスタの機能を解放する鍵となり、分散ワークロードはネットワークに依存していると記載しました。高価なGPUコンピューティングが AI データセンターの全体コストを押し上げるため、ネットワークが GPU パフォーマンスやトレーニング ジョブの完了時間のボトルネックになってはなりません。
上記の Terraforming Apstra をどの用に実現するかを試したい場合は、Apstra Cloud Labs の無料トライアルを試すことができます。トライアルは、こちらから依頼することができます。
Apstra インテントベースのオペレーションと AIOps により、Juniperは企業としてあらゆる種類の推論およびトレーニング ワークロードに対して優れたネットワーク エクスペリエンスを提供します。Apstraでは構築の自動化だけでなく、AIクラスタに必要な可視化も利用できます。可視化については別の記事でお伝えします。
高性能 AI クラスタを確保するための包括的なポートフォリオを詳しく解説するAI clusterのポータル ドキュメントの今後の拡張にご期待ください。Juniper では、オープン性の取り組みと、エクスペリエンス最優先の運用アプローチを重要視しています。今後Infinibandに匹敵するようなAI Clusterのパフォーマンス情報、マルチテナントの実現方法、AI Clusterに必要な機能情報、Apstraの可視化情報などについても公開予定です。