こちらの記事はblog.juniper.netに掲載されている"Managing the Elephant in the Room for AI Data Centers 2024.3.20"の抄訳と、補足を追加した記事です。
AI/MLワークロードのインテリジェントな負荷分散
"イーサネットによる AI/ML データセンター ネットワーキング概説" にも記載したように、データセンターの AI/ML ワークロードは、「エレファント フロー」と呼ばれる、長時間に広帯域のトラフィックとなる、独特のトラフィックを生成します。
これらの大量のRDMAトラフィックは、通常、AI サーバーのGPUによって生成されます。
これらの GPU がこれらのエレファント フローを生成する理由を理解するには、大規模言語モデル (LLM)、画像分類、ビデオ オーディオ分析など、AI トレーニングでデータが果たす重要な役割を理解することが不可欠です。
AI トレーニング・学習概要
AIを利用する過程の、最初のステップでもあるトレーニング フェーズでは、特定のデータベース、クラウド ストレージ、Wikipediaなどのさまざまなソースからデータを収集します。次に、データ サイエンティストやエンジニアがデータを処理して、各ピースにラベルを付けたりトークン化したりします。これらのトークン/データ セット/入力は、期待される結果を生成するようにトレーニングされます。たとえば、オンラインで欲しい情報のクエリを入力すると、LLM で関連する回答を求めます。期待する回答を応えられるようにするには、通常大きくて重いデータセットを利用し、トレーニングする必要があります。そのため、モデルをトレーニングするには多くの GPU が必要であり、ペタバイトを超えるデータを処理します。通常、これらの大きくて重いデータはバッチに分割され、いくつかの並列メカニズム (データ並列処理/モデル並列処理など) が使用されます。処理されたデータがトレーニング モデルに入力された後、GPU クラスターは算術計算/トレーニングを実行して、目的の結果を取得します。各 GPU トレーニング計算の出力は、クラスター内の他の GPU と同期して、調和のとれたビューを実現する必要があります。これは、すべての GPU トレーニング結果の出力をクラスター内の他のすべての GPU に送信することによって行われます。このトラフィック フロー (メモリ転送) は、RoCEv2 などの特殊なストレージ トランスポート プロトコルを使用し、このトラフィック フローを「エレファント フロー」と呼びます。
RoCEの利用
AI モデルをトレーニングするためには、GPU クラスターを使用して複雑な数学的計算 (浮動小数点演算または FLOPS) を実行し、膨大な量の結果を並列で生成します。これにより、AI モデルの配信とトレーニングを高速化できます。ジョブ間を移動する場合、トレーニング モデルの勾配/メモリ チャンクをクラスター内の 1 つの GPU から他の GPU に転送して、出力を同期させる必要があります。そのため、分散 GPU サーバー間でこれらの結果を同期するには、RDMA over Converged Ethernet バージョン 2 とも呼ばれる RoCEv2 トランスポート プロトコルを使用します。RoCEv2 は、サーバー CPU が関与したり、GPU NIC が状態を維持したりする必要がないため、データ転送用の一般的なプロトコルになっています。そのため、従来のストレージ データ ネットワークでのみ使用される NVMEoTCP などの TCP ベースのデータ転送よりもスケーラビリティに優れています。また、LLM やその他のドメイン固有のトレーニング モデルに関するソフトウェア開発の新しい進化では、異なるサーバー ノードで並列コンピューティング パワーを使用し、ジョブを完了する前にそれらの状態を継続的に同期します。これは、イーサネット ネットワーク上のGPU間のネットワークである、 DC バックエンド ファブリック全体で膨大な東西データ交換を意味します。したがって、ファブリック帯域幅の使用が効率的であり、エントロピーの低いワークロードの状況でも適切に機能することを保証する必要があります。ただし、以前の記事にもあるようにさまざまな箇所でトラフィックの輻輳が発生する可能性があります。そのため、バックエンドAI データ センター ネットワークでは、次の特性を保証することが重要です。
-
リーフとスパイン間の複数の 400G/800G リンクを使用した効果的な IP ECMP ロード バランシング 。
- サーバーの GPU 間で大きなデータ ピースが東西に転送されます。そのため、フレームを失うことなくすべてのデータを同期するには、ファブリック全体の帯域幅を有効に活用する必要があります。
- 輻輳管理および緩和技術 (PFC-DSCP (優先フロー制御) および ECN (明示的輻輳通知))、および DCQCN を介した両方の技術の調整。
ロードバランシング技術
このブログでは、AI データ センター ファブリック内の効率的なロードバランシング技術に焦点を当てています。
AIデータセンターではトラフィック輻輳を発生させないように管理することが重要であり、データセンターのファブリックのECMP環境にあるリンクをどのように効果的に利用するかを考慮する必要があります。ECMP環境では複数のリンクを使ってロードバランシングしますが、ロードバランシングの効率を高めるには様々な方法があります。リンク品質に関するローカルノードレベルの認識のみを使用するものもあれば、最適なパスを選択するためにローカルリンクとリモートノードの両方の品質性能を使用するものもあります。
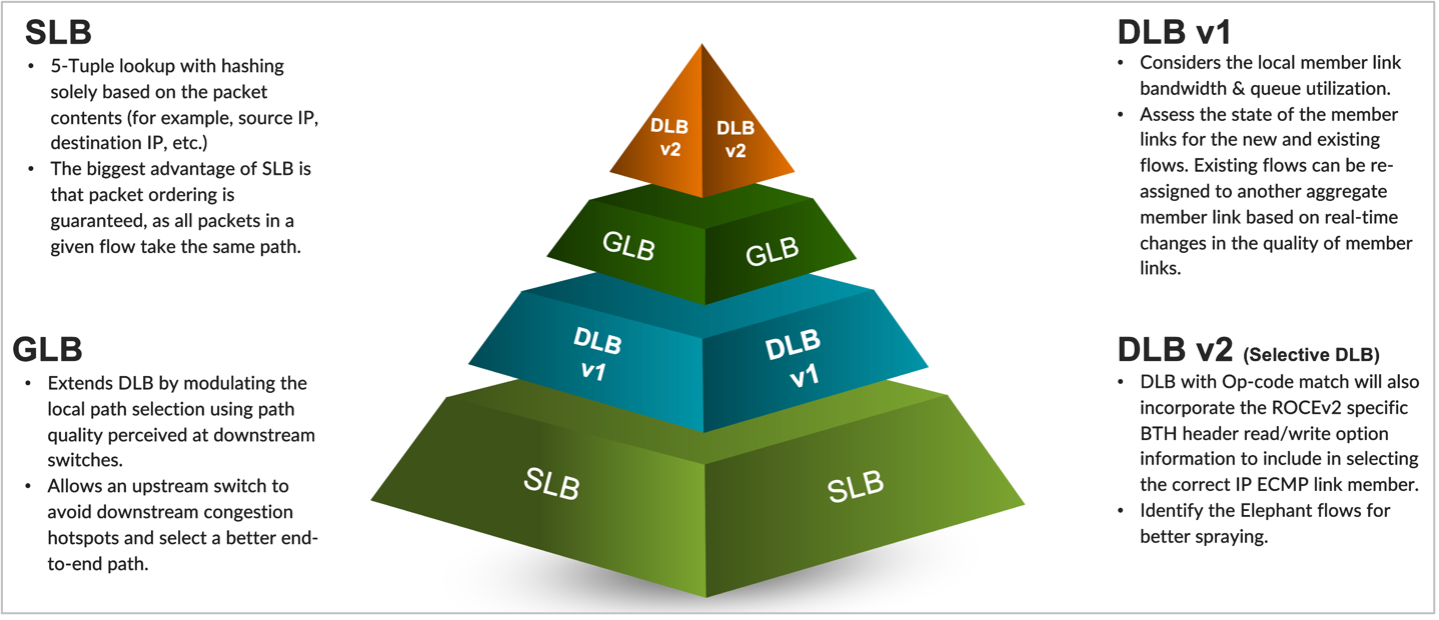
これらの技術は、ロードバランシングに対する 4 つの異なるアプローチに分類できます。
-
オプション 1: 静的ロード バランシング (SLB:Static Load Balancing) は、フロー毎の負荷分散手法を行う、従来の負荷分散手法であり、パケット形式とパケット エントロピー特性のみを考慮します。IP ECMP メンバー リンクとそのキューのリアルタイム使用状況を評価することはせず、通常、AI/ML ファブリックのコンテキストでは使用されません。
-
オプション 2: 動的ロード バランシング (DLB:Dynamic Load Balancing) は、特定のファブリック ノード レベルでのローカル リンク帯域幅の使用率とキュー サイズを考慮します。これにより、最適なリンクだけでなく、フローに適した正常なリンクも選択され、トラフィックのスムーズなフローが確保されます。
-
オプション 3: グローバル ロード バランシング (GLB:Global Load Balancing) では、リンク品質に関する次のホップ (NNH:Next Next Hop) 情報 (ローカル リーフだけでなく、新規または既存のフローに使用する最適なメンバー リンクを選択するスパイン リンクの機能も含む) と、リンクローカル帯域幅およびキュー サイズを含むパス選択アルゴリズムが使用されます。
- オプション 4: DLB v2 またはセレクティブDLB により、特定のフローのみを識別して、ロードバランシングメカニズムを選択することで、特定パケットのみパーパケットのロードバランスの利用を可能にします。パーパケットのロードバランスを行う場合は、パケットのリオーダーが発生する可能性があるため、NIC側がリオーダーに対応する必要があります。特定のフローを選択するときには、InfinibandのOp-code 情報も含むこともできます。
静的ロードバランシング (SLB)
静的ロードバランシング (SLB) は、従来のイーサネット スイッチングおよびルーティングで、異なるリンク間のネットワーク トラフィックのバランスを取り、帯域幅を効果的に使用するためによく使用されます。これは、さまざまなアプリケーションが使用される従来のサーバー展開ではうまく機能しました。SLB は、パケット ヘッダーの機能からハッシュ値を計算することに基づいています。イーサネット フレームでは、Ether タイプ ヘッダーに、送信元/宛先 IP、送信元/宛先 UDP/TCP トランスポート層、およびエントロピーを持つプロトコル タイプが含まれています。この 5 つの負荷分散ハッシュは充分に思えるかもしれませんが、残念ながら、AI サーバーおよび RDMA GPU トラフィックに常に適しているわけではありません。RDMA トラフィックのエントロピーは非常に低くなります。つまり、パケット内の変動レベルが低く、フローは常に同じリンクを使用する可能性があります。SLB メカニズムは、ローカル リンクの帯域幅使用量とキューの深さを考慮せず、フローをリンクに割り当てる前にリンクの健全性をチェックしません。高帯域幅を伝送するリンクに特定のフローが割り当てられ、空きリンクが十分に活用されないままになる可能性があります。すなわち、効果的な分散が出来ずに輻輳が発生する可能性があります。これらの問題に対処するには、AI および GPU トラフィックに対して代替のロードバランシング方法を検討する必要があります。
動的ロードバランシング(DLB)
- パーパケット(per-packet)のスプレー モード
同じフローのパケットが IP ECMP グループのリンク メンバー全体にスプレーされます。このモードでは、リオーダーが発生し、受信側で期待していた順序でない順番で受診する可能性があります。パケットのリオーダーに対応するために NIC 側で対応する必要があります。 - フローレット(flow-let) モード
フローの種類と継続時間に基づいてアクティブなフローを判定し、現在の帯域幅使用率に基づき最適な送信リンクを決定します。アクティブなフローは非アクティブタイマーにより識別し(set ecmp-dlb flowlet inactivity-interval (micro seconds))、タイマー内であれば同一のフロートして同一のリンクを利用します。 - アサインドフロー(Assigned-Flow)モード
DLBでは上記2つのほかに、アサインドフローモードもあります。これは、問題の原因を切り分けるときに利用します。このモードでは、ポートの負荷やキューのサイズは考慮せず、最初のパケットが利用するリンクを決め、一定期間、リバランスを選択的に無効にするために使用できます。
グローバルロードバランシング(GLB)
AI データセンター ファブリックでは、ローカル リンク品質に加えてリモート リンク品質テーブルを作成することがベスト プラクティスです。これは、スパインが多数のリーフ ノードからのトラフィックを集約し、リンク品質の低下が発生する最も一般的な場所となるため、特に有効です。GLB を実装する際の課題は、情報をマイクロ秒レベルで定期的に更新する必要があることです。これは、スイッチのハードウェア ASICが対応する必要があり、それらが分散して配置される必要があります。 CPU ベースのカーネル実装として、コントロール プレーン プロトコルを使用しては不可能です。これは、集中型から完全に分散型のハードウェア実装へと進化した業界の BFD 実装に似ています。
DLB v2 (セレクティブ DLB)
2 つのDLBのロードバランシングのモード (フローレットとパケットごとのスプレー) の主な特徴を記載しました。DLBでは、スイッチ全体で有効化する必要があります。DLB v2 モードでは、特定のフローを識別し、それらのフローに対してパケットをスプレーします。ユーザー定義のフィルターを使用して特定のフローを識別し、DLB にマッピングできます。RoCEv2 BTH ヘッダーの Op コード一致を使用してそれらのフィルターを識別することもできます。これは通常、サーバからのパケットに異なる処理を施すのに適したオプションです。スイッチでのアクセス リストの有効な入力に基づいてパケットの特定の処理を有効にするには、フローの特性と TCAM スペースの割り当てを理解する必要があります。前のセクションで述べたように、パケット モードによって順序が乱れたパケットが発生する可能性があり、これはすべてのフローに望ましいとは限りません。特定のOpコードを選択して、特定のロード バランシング モードを利用するパケットを指定することもできます。この同じルールを AI DC ネットワークの特定のストレージまたはデータ同期操作に適用することができます。
ロードバランシングメカニズムのまとめ
400Gbps/800Gbpsや将来的な1.6Tbps IP CLOS ファブリック の展開を検討する場合、リンク速度とその活用方法はどちらも重要です。特定のユースケースではSLB などの従来の基本的な負荷分散メカニズムで十分な場合があります。ただし、AI/ML データセンターなどのより複雑な展開では、DLB と GLB を利用することで、エンドツーエンドで最低なリンクを選択することができ、最高のパケット転送パフォーマンスと最も効率的な帯域幅利用を実現します。前述の AI/ML ネットワークロードバランシング技術の一部は、並行して有効にすることもできます。たとえば、DLB は GLB の利用時にローカルノードで適用されたり、特定のファブリック内で複数のリンクが有効になっている場合に適用されます。AI データセンター実装では、ネットワーク アーキテクトは、特定のロードバランシングを有効にする RoCEv2 オペレーション (オペコード) の種類を自由に設定することもできます。また、ロードバランシング技術の有効性はハードウェアシリコンに大きく依存することを理解することも重要です。これは、トラフィックとロードバランシングをマイクロ秒またはナノ秒レベルで実行する必要があり、迅速な処理時間が求められるためです。ロード バランシングは、データ センターでは長年にわたり一般的な手法となっています。これは、データ センターでは通常、アプリケーションの多様性が高く、同じスイッチに入るフローの数が多く、東西通信と南北通信が混在しているためです。ただし、従来のロード バランシング方法は、新しい AI/ML バックエンド データ センター ネットワークには適していません。AI/ML クラスター スイッチング インフラストラクチャの場合、一般的な通信パターンは東西であり、バックエンド イーサネットで実行されるアプリケーションの数は比較的少ないです。通常、RoCEv2 トランスポートのみが使用され、アプリケーションに関しては他には何も使用されません。これが、最近の動的ロード バランシングの開発が IP ECMP グループの帯域幅使用率に依存している理由です。DLB の場合はローカル帯域幅使用率が使用され、GLB の場合はローカルとリモートが使用されます。今後数年間で、ロード バランシングのより高度な機能が市場に登場してくると予想されます。